
Today it’s pretty common or even a must for a purchaser to monitor and compare prices before making an on-line order. Price is one of the key factors that guides the decision to buy a product or not. That is why web shops can’t afford to miss it. They will have to monitor prices regularly to see how their prices compare to the real market level.
Why to use price monitoring in ecommerce?
To analyze market competition:
First of all, it allows companies to adjust prices for their products to the current market situation. For example:
A company that sells sport shoes, let’s say at 100 euro per pair, will lose customers if competitors sell sport shoes of the same type and quality at 70 euro. It will also lose (or receive less) revenue if customers are ready to buy the same sport shoes at 500 euro per pair. Price monitoring helps a company not to face any of these scenarios.
To control resellers in following recommended prices:
Fixing recommended prices is a trade agreement where manufacturers announce product prices directly to the end customer. A reseller “gets” a percentage of the announced product price from the manufacturer but can’t decide it itself. The scheme works when the manufacturer has a strong market brand. Even though, there is not always a guarantee that resellers follow recommended prices. And here again price monitoring is crucial.
By monitoring prices, you can:
- fix competitive prices;
- increase sales volumes;
- negotiate more favorable terms with contractors;
- timely react on the changes in the market;
- know what answers purchasers get, if they ask for a kind of cost justification.
It means that by monitoring prices you make your web-shop more attractive and
competitive.
There are several ways to monitor prices online
Monitoring by your own
To track prices in online stores, you need to visit them regularly, enter manually a product page, collect prices, save them somewhere, for example, in an Excel spreadsheet. The process takes a lot of time and effort. If you have a lot of products and at least 5+ competitors, you may need employees who will deal only with this.
Collect prices automatically
Automatic price collection means a robot visiting pages in certain intervals, collecting prices and saving them. Then speed is very high and once developed such application may only need some support. At a certain time, Robot goes through all specified pages, collects prices and as an example sends results to a responsible person by e-mail.
Moreover, technologies allow to collect automatically and arrange not only prices, but any other information as well. For example, a list of products from various suppliers, new customer reviews on popular on-line resources, or reaction on changes in search results. In general, it’s a collection of certain data on public or private resources and informing a responsible person on the results.
How to select proper tools?
Most up-to-date online stores partially or fully use functions of rendering content on the client side (working with dynamic DOM) (for example, Angular / React with a request for price of a specific product via the API). To get a price of a product it’s not enough just to download a page with this product and pull the price by selector. Data collection should be made using a browser that is controlled by the application.
There are services that make all the work on launching a browser, processing JavaScript and serving content via API. With them there’s no need to deploy infrastructure and develop yourself a data delivery application, services like Scraping-Bot, Scrapeworks, Diggernaut, ScrapingBee, Scraper API.
But it happens that they can’t be used due to the following reasons:
- A very high price per a unit of data. For example, price of one product should be checked 2 times a day, in the morning and evening. There may be 500 products, and there are 15 stores which we want to react on. That means per day we need to spend money on 7500 up to 15000 requests.
- Limited configuration options. For example, when collecting the prices you cannot change the default location of a targeted store without adjusting or customizing the service, so that your result is limited to 1 region.
- We have to disclose information to the service provider, for example, a list of products, targeted stores, and etc.
To stay out of limitations and build a flexible solution we preferred writing an own script. The connected software was mostly developed in Angular (Typescript) so we selected NodeJS + Typescript for parser back end.
And picked NigthmareJS library as a browser automation tool as it is easy to use, fully supports HTML5 and is extensible. It let opening an Electron instance on the Chromium engine. Since Chromium is used, a website behaves like in other JavaScript browsers in a managed instance. So, dynamic content is displayed on the page and can be retrieved for further manipulations with data.
What is the solution about?
Control commands are chains. Each command returns a promise, that let you code in promise, async function or generator style. After the page is loaded, Nightmare injects JavaScript control code into the page instance, which allows using commands emulating actions of a browser user, commands like goto, type, click, …
Then you can also include your own commands directly working with Chromium devapi to the execution code.
The simple code looks like:

Short, textual explanation of the code
Connect a library, create an object with a visible browser mode –
go to the page, search for an element using a CSS selector –
enter text –
click on a button –
wait for a new CSS selector to appear, execute a function on the browser side and return it –
in the end of the chain of tasks, the result will be passed to “then” or an exception will be thrown.

How looks like a parser structure in general?
- Download a list of products and stores
- Connect browser control library to our script
- Go to all the links one by one
- Wait until the page is loaded then selector with the price is on the page. Or, there are other key selectors, for example, the selector with an error.
- Collect data from the required block
If necessary, process data, structure it and save, or send the result in a handy format.
What is the structure of our solution?
- Include Nightmare
- Go to the required URL
- Wait until the price selector is present on the page or other key selectors are present (for example, a selector with an error)
- Pick up the resulting HTML
- Parse the price using Cheerio, for example
Main problems and how to solve them
Getting blocked
Most sites are configured with basic or advanced protection against automatic data collection. Basic ones can be bypassed by using proxy servers with control of requests number to the site. The advanced protection can be attributed, for example, by putting the site behind CloudFlare. In this case, you can’t skip using services that solve captcha via API.
Exceeding of waiting time
It happens when the server doesn’t have enough time to give data away due to an error on the server-side, high load, etc. These cases should be tracked, and failed attempts added to the queue again. If a site can’t present a page several times in a row, for example, 5 times, it has to notify the end-user about the error with the code and status of the error. This allows to configure robot more accurate, as well as receive feedback from the end-user about the program.
Style changes
HTML structure of a site can change quite often. Due to dynamically changing conditions, robot configuration should be at least moved to the configuration file to indicate parameters by which the robot gets information from a specific site. The configuration may contain parameters like site name, desired price selector, site error selector (if we catch an error, we need to know where the error was thrown).
It will help to change the configuration of the robot dynamically when the site structure changes. If a client has some CSS skills and can choose an intended selector himself, this config can be brought to the admin panel or at least to a google spreadsheet document. There the client can set the proper selectors himself. It saves a lot of time and costs in case of small changes as there’s no need to contact the developer.
Queuing and parallel execution
If we need to get a price of 500 products from 20 online stores, we have to collect data in parallel, simultaneously from several resources. Getting data from one page of a site on average takes 1-3 seconds without using a “headless browser”, and about 5-7 using it. To organize a queue, you can use ready libraries of the «queue-promise» type for Node.js.
Launching costs
Bear in mind that using a “headless browser” is a high load for RAM. Since Chromium is under the hood, you’d rather have at least 400 megabytes of memory available for one robot process. As evidenced in practice if there’s a lack of memory, the data collection application does not close with error but starts working at a low speed.
A need to deploy with XVFB
Again, as Chromium is under the hood, it needs to draw the result of the work somewhere. Then it requires to use XVFB on the servers. XVFB is a server of a display that executes X11 display server protocol. Unlike other display servers, XVFB performs all graphics operations in virtual memory without any output to the screen.
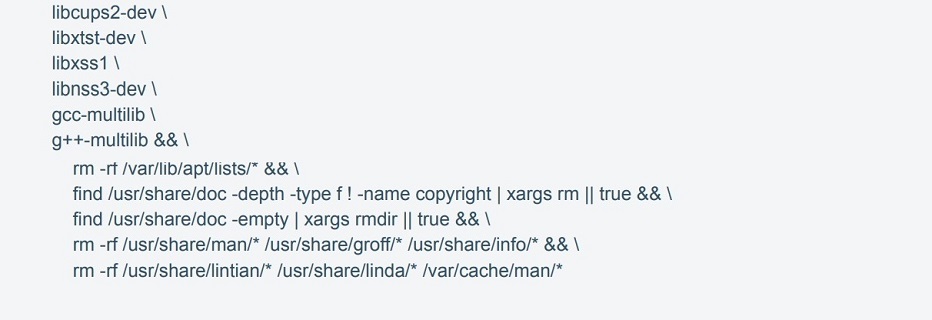
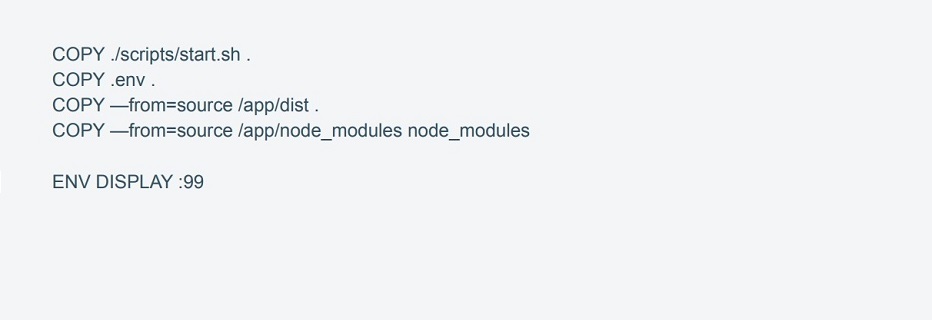
Docker container with a pre-defined configuration is used to deploy the application. If necessary (for example, for reducing data collection time), it allows you to deploy new application servers with all the required dependencies quickly.



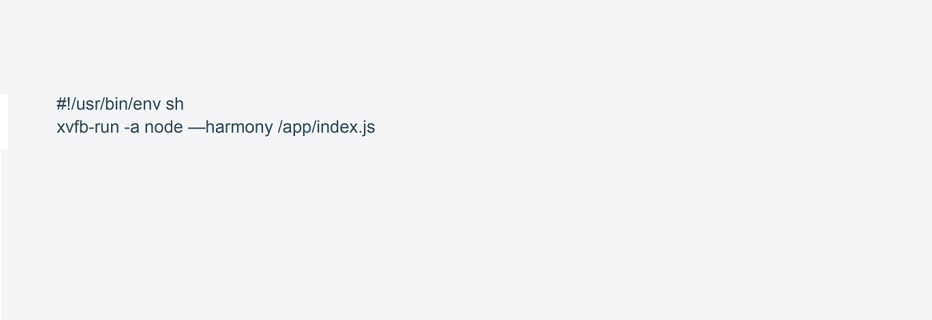
Start script sh that uses xvfb-run is responsible for starting the application.
Choosing a store region
Some web-shops use different prices in different regions. To compile configuration, you must check manually how a website stores information about the region of a selected user. Usually, it is subdomain, or cookies.
To inject cookies in Nightmare, before using the library you do:



And further to upload cookies to the instance we use:

Catching errors
Each action call will be either fulfilled, or an exception will be thrown. Therefore, in places where code may be executed not for a certainty, you need to wrap requests into “try catch” and handle them accordingly. “Wait” (selector) is an example, this instruction gives a command to pause script execution until the html element with the corresponding CSS selector appears. The module has a default timeout (that can be changed optionally). When it occurs, an exception will be thrown. So, it’s possible to handle why something is absent on the page and react on it in a certain way.
SUMMARY
Price monitoring is essential to run a business successfully. It’s hard to take a leading position on the market without monitoring prices, whatever industry your company operates in. No matter how unique and innovative the product is, a company cannot succeed without a proper marketing policy.
Competitive price monitoring robots enable companies to automate price changes for thousands of products at once. They don’t just change prices, but they do it intelligently. Competitor prices, stock availability, market demand and number of other factors are all considered. With the proper price monitoring tools, you can focus on other equally important business processes.

Author
Dmitry Ropotan, Tech Lead, E-commerce
Dmitry is a Senior expert with 9+ years IT background. He has wide experience in working for international companies and in multinational distributed development teams, implemented multiple projects in e-commerce, B2B & B2C portals.


